Backgroud
IPVS can be used as a load balancer to provide virtual services, and it is common to use the IPIP protocol to preserve client IPs. The typical traffic flow is as follows:
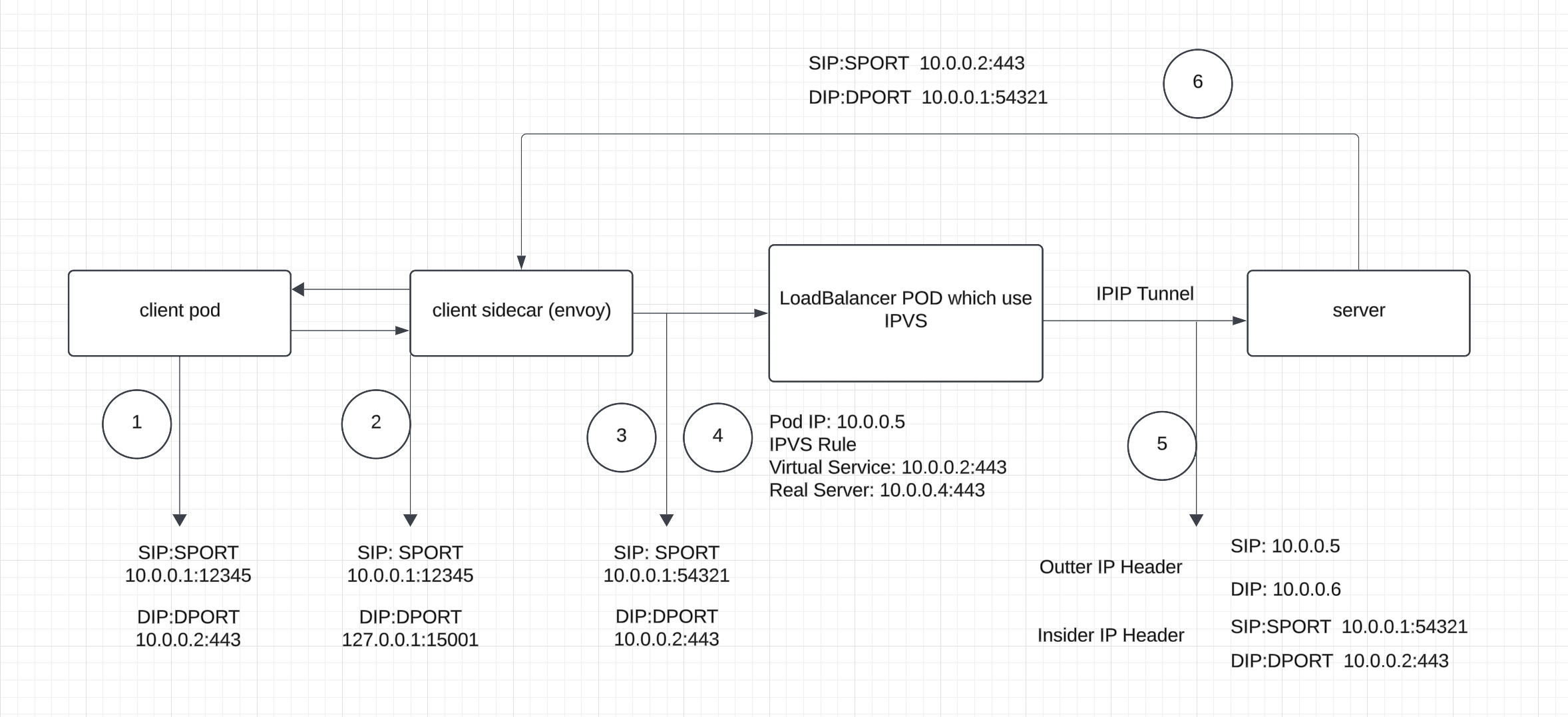
The client pod has envoy sidecar injected.
Recently, some customers have reported that their requests have a high timeout rate after moving to this network flow.
-
The client creates a new connection to the VIP 10.0.0.2:443 with the client IP 10.0.0.1 and port 12345 (using 12345 as an example). The connection is 10.0.0.1:12345 → 10.0.0.2:443.
-
Iptables rules intercept the request and redirect the traffic to port 15001, changing the connection’s destination IP and port to 127.0.0.1 and 15006. The connection is now 10.0.0.1:12345 → 127.0.0.1:15006.
-
After the TCP handshake succeeds, the client sends an SSL hello on the established connection. The sidecar’s Envoy receives the request from the loopback (lo) interface. Since the outbound traffic is passthrough, Envoy does not perform any checks at the HTTP/HTTPS layer and creates a new connection to the destination 10.0.0.2. The request is forwarded to the VIP 10.0.0.2 with the connection 10.0.0.1:54321 → 10.0.0.2:443.
-
The load balancer uses IPVS with the IPIP packet forwarding method and has the following IPVS rule:
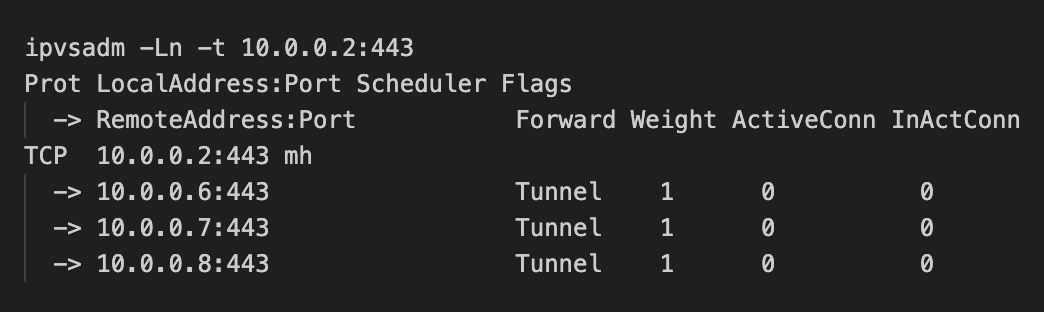
-
The TCP SYN packet from 10.0.0.1:54321 to 10.0.0.2:443 is forwarded to a real server with an IPIP tunnel header, where the outer IP header has the source IP 10.0.0.5 (load balancer’s IP) and the destination IP 10.0.0.6 (real server’s IP), while the inner IP/TCP header remains unchanged..
-
After receiving the TCP SYN packet from 10.0.0.1:54321 to 10.0.0.2:443, the real server strips the outer IP header, processes the request, and sends TCP SYN,ACK directly to the client, bypassing the load balancer
The sidecar(envoy) in the client side and Loadbalancer only handles the request in the TCP layer, so the TLS and HTTP interaction happens between the client and server directly.
Tcpdump Analysis
We used TCPDUMP to check why the request was delayed, here is the dump result:
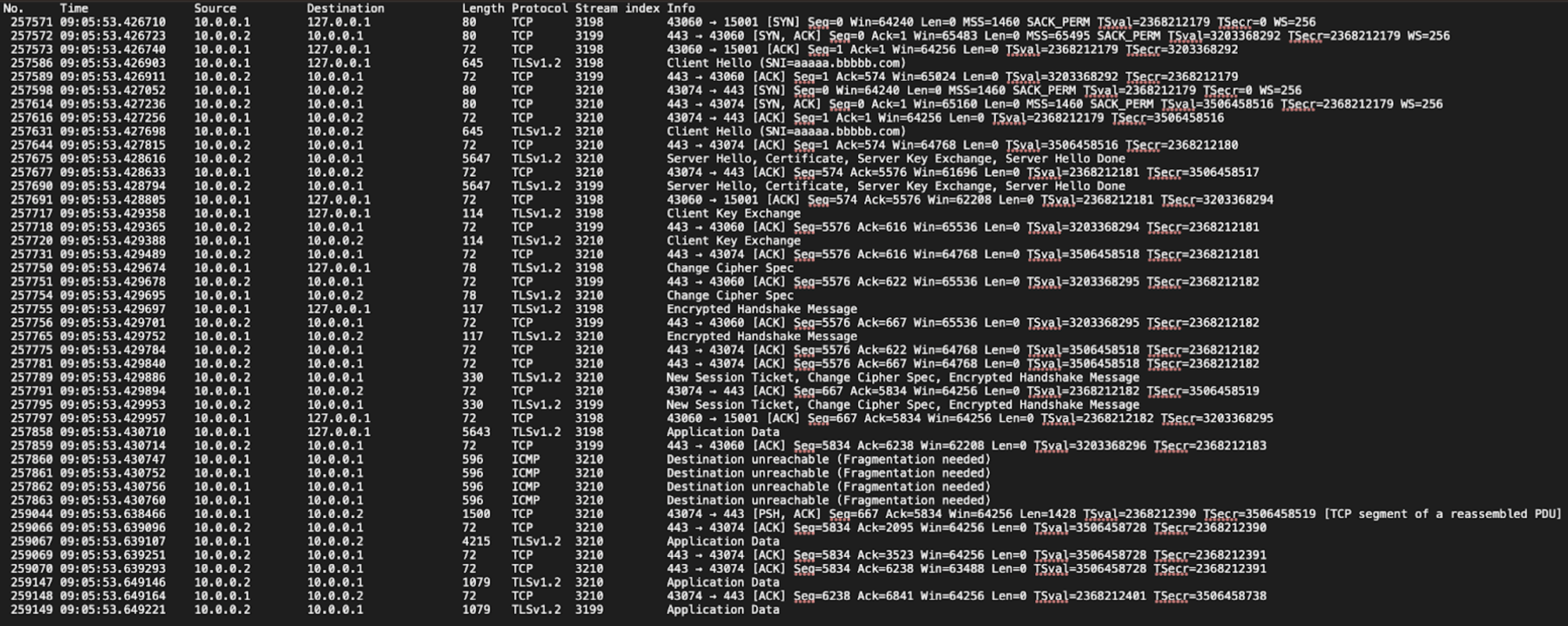
This is the tcpdump file captured from the ‘lo’ and ‘eth0’ interfaces on the client side..
- Packets numbered 257571 to 257797 are TCP and TLS handshake packets.
- Packet number 257858 is sent from the client and received on the ‘lo’ interface.
- Instead of forwarding this packet directly to 10.0.0.2, there are four ICMP packets with the source IP 10.0.0.1 and destination IP 10.0.0.1 that were captured.. The details of this ICMP packet:
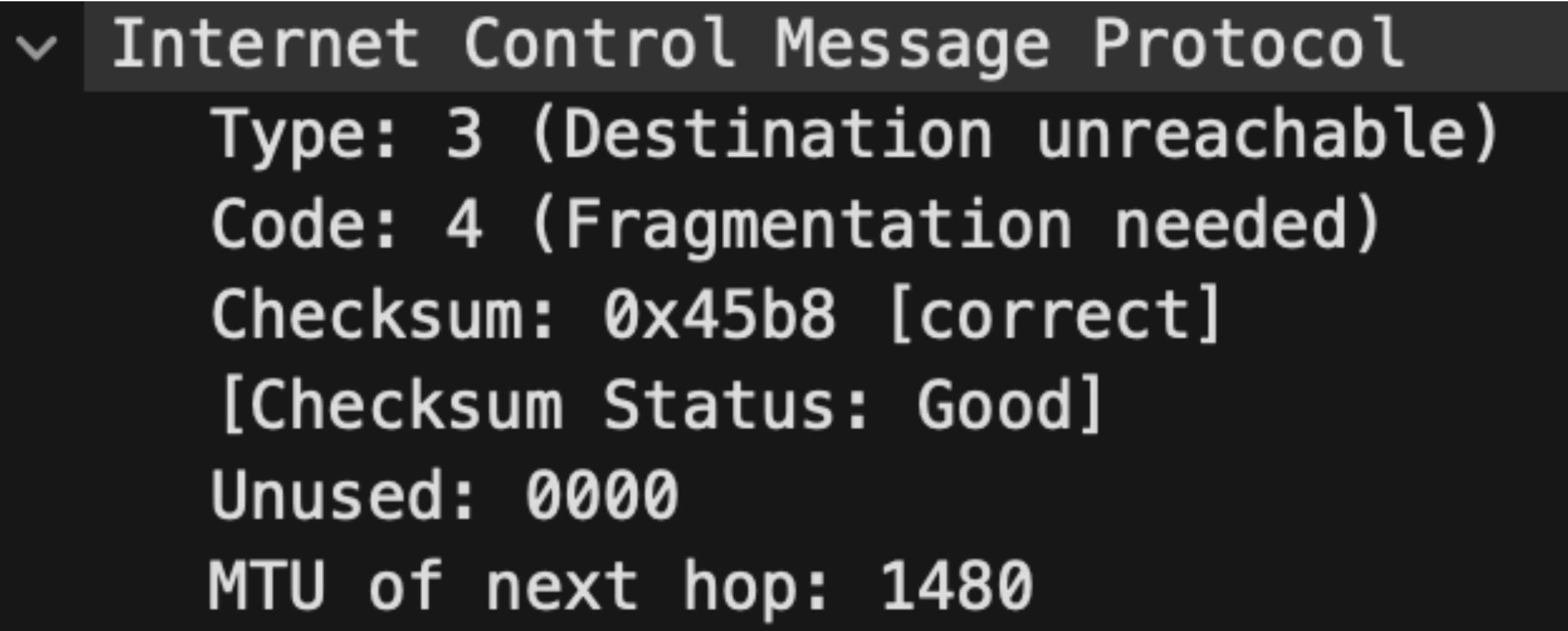
- Packet number 259044 is the first packet sent from 10.0.0.1 to 10.0.0.2. The timestamp is 09:05:53.638466, indicating a delay of approximately 207.76 ms compared to the timestamp 09:05:53.430710 of packet number 257858.
But the strange thing is, there was another request almost at the same time, but it exhibited different behavior.
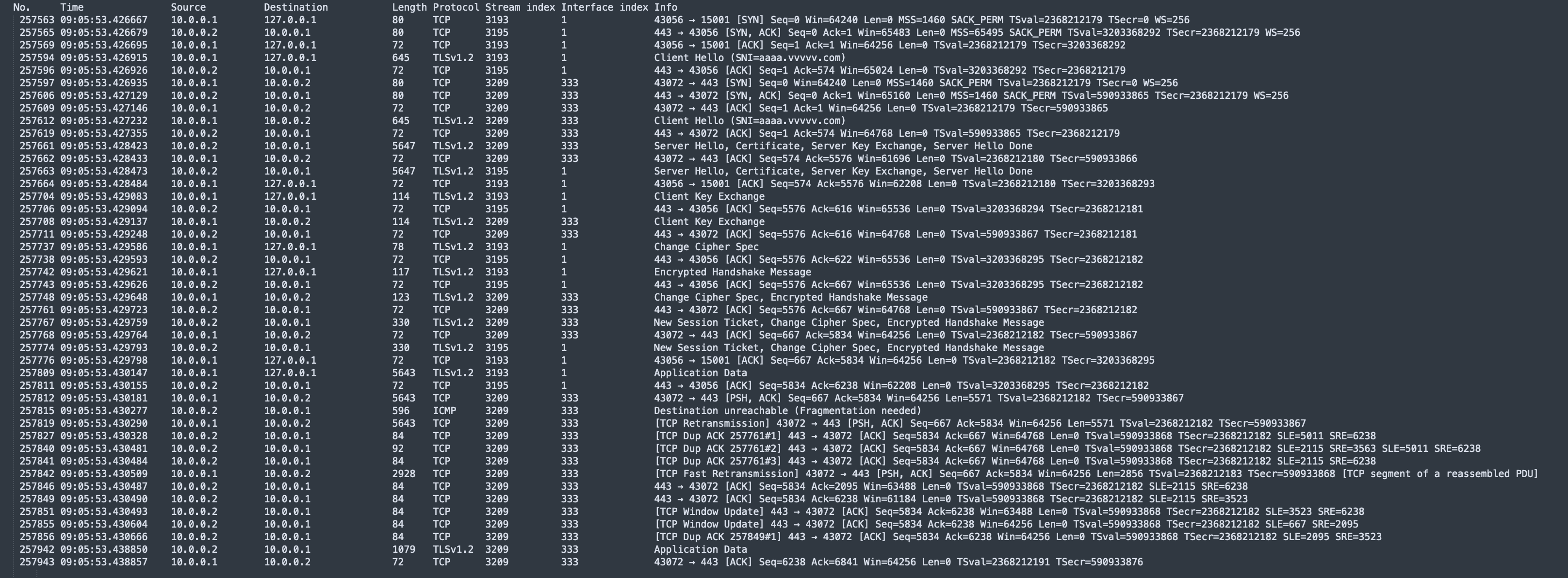
- Packets numbered 257563 to 257776 are the TCP and TLS handshake packets.
- Packet number 257809 is the packet sent from the client and received on the loopback (lo) interface.
- Then, packet number 257812 is the packet that forwards the contents of packet number 257809 to 10.0.0.2.
- Then, a destination unreachable ICMP packet was received from source IP 10.0.0.2 to client 10.0.0.1 (packet number 257815).
- Packet number 257819 is the retransmission of packet number 257812, with only a 0.1 ms time difference between 09:05:53.430290 and 09:05:53.430181.
This request (referred to as request A below) occurred slightly earlier than the previous request (referred to as request B below), which encountered issues. It seems that packet number 257815 triggered something in the TCP stack, ultimately causing a 200 ms delay.
ICMP destination unreachable packet
This error message occurs when the size of a packet exceeds the Maximum Transmission Unit (MTU) of the interface that needs to route it. Since IP Virtual Server (IPVS) adds an extra IP header for IPIP tunneling, it increases the packet size by 20 bytes. This change in packet length can lead to issues if the packet is marked with the ‘Don’t Fragment’ (DF) flag. In such cases, IPVS will send an ICMP Destination Unreachable message back to the client..
static inline bool ensure_mtu_is_adequate(struct netns_ipvs *ipvs, int skb_af,
int rt_mode,
struct ip_vs_iphdr *ipvsh,
struct sk_buff *skb, int mtu)
{
#ifdef CONFIG_IP_VS_IPV6
if (skb_af == AF_INET6) {
struct net *net = ipvs->net;
if (unlikely(__mtu_check_toobig_v6(skb, mtu))) {
if (!skb->dev)
skb->dev = net->loopback_dev;
/* only send ICMP too big on first fragment */
if (!ipvsh->fragoffs && !ip_vs_iph_icmp(ipvsh))
icmpv6_send(skb, ICMPV6_PKT_TOOBIG, 0, mtu);
IP_VS_DBG(1, "frag needed for %pI6c\n",
&ipv6_hdr(skb)->saddr);
return false;
}
} else
#endif
{
/* If we're going to tunnel the packet and pmtu discovery
* is disabled, we'll just fragment it anyway
*/
if ((rt_mode & IP_VS_RT_MODE_TUNNEL) && !sysctl_pmtu_disc(ipvs))
return true;
if (unlikely(ip_hdr(skb)->frag_off & htons(IP_DF) &&
skb->len > mtu && !skb_is_gso(skb) &&
!ip_vs_iph_icmp(ipvsh))) {
icmp_send(skb, ICMP_DEST_UNREACH, ICMP_FRAG_NEEDED,
htonl(mtu));
IP_VS_DBG(1, "frag needed for %pI4\n",
&ip_hdr(skb)->saddr);
return false;
}
}
return true;
}
The details of this ICMP packet also include the MTU information, which is 1480..
The MTU setting is 1500 at each hop in the entire traffic flow. However, IPIP tunnels require the injection of an additional IP header, which is 20 bytes. This is why IPVS requests the client to send packets with an MTU of 1480.
If we change the MTU of the interface or the route to 1480 on either the client or server side, this issue can be resolved. But there are still something not clear:
Question 1: How does the ICMP destination unreachable packet impact the client behavior?
Let’s examine the source code to understand how Linux handles ICMP Destination Unreachable (FRAG NEEDED) packets.
You can find the relevant code here:
Upon receiving an ICMP Unreachable packet, the system begins to adjust the MTU through the icmp_socket_deliver() function, which calls tcp_v4_err().
if (code == ICMP_FRAG_NEEDED) { /* PMTU discovery (RFC1191) */
/* We are not interested in TCP_LISTEN and open_requests
* (SYN-ACKs send out by Linux are always <576bytes so
* they should go through unfragmented).
*/
if (sk->sk_state == TCP_LISTEN)
goto out;
WRITE_ONCE(tp->mtu_info, info);
if (!sock_owned_by_user(sk)) {
tcp_v4_mtu_reduced(sk);
} else {
if (!test_and_set_bit(TCP_MTU_REDUCED_DEFERRED, &sk->sk_tsq_flags))
sock_hold(sk);
}
goto out;
}
If the socket is not held by user, the MTU is reduced immediately using tcp_v4_mtu_reduced(). However, if the TCP socket is held by user, the TCP small queue flag TCP_MTU_REDUCED_DEFERRED will be set. Once the socket is released by user, tcp_release_cb() is called to process the queue, and tcp_v4_mtu_reduced() is invoked.
You can find more details here:
So after the ICMP packet has been handled, the route MTU will be changed to 1480 and linux kernel will keep this MTU cache for 600s.
ip route get 10.0.0.2
10.0.0.2 via 10.x.x.x dev eth0 src 10.0.0.1 uid 0
cache 421
net.ipv4.route.mtu_expires = 600
net.ipv6.route.mtu_expires = 600
Question 2: Why are there multiple ICMP Destination Unreachable (FRAG NEEDED) packets with the source IP equal to the destination IP?
Let’s trace the kernel stack of the function icmp_send(skb, ICMP_DEST_UNREACH, ICMP_FRAG_NEEDED, htonl(mtu)). The icmp_send() function in the Linux kernel is responsible for sending this ICMP packet. By tracing it, we can understand how this is triggered:
__icmp_send
__ip_finish_output
ip_finish_output
ip_output
ip_local_out
__ip_queue_xmit
ip_queue_xmit
__tcp_transmit_skb
tcp_write_xmit
__tcp_push_pending_frames
tcp_push
tcp_sendmsg_locked
tcp_sendmsg
inet_sendmsg
sock_sendmsg
sock_write_iter
do_iter_readv_writev
do_iter_write
vfs_writev
do_writev
__x64_sys_writev
do_syscall_64
entry_SYSCALL_64_after_hwframe
From the call stack, we can see that it checks the route MTU and attempts to perform IP fragmentation. If the DF (Don’t Fragment) bit is set in the IP header, the kernel will send an ICMP packet with type 3 (ICMP_DEST_UNREACH) and code 4 (ICMP_FRAG_NEEDED).
There were two requests occurring almost simultaneously. The first request triggers the ICMP Destination Unreachable packet from the load balancer, which then changes the route MTU to 1480. The second request performs MSS (Maximum Segment Size) negotiation based on an MTU of 1500, but the route MTU has already been changed to 1480. Thus, when the packet length exceeds 1500, an ICMP packet with type 3 (ICMP_DEST_UNREACH) and code 4 (ICMP_FRAG_NEEDED) is sent from the kernel with the source IP equal to the destination IP.
If we examine the statistics in the Linux kernel using netstat, we can see some relevant data:
Icmp:
6957 ICMP messages received
22 input ICMP message failed
ICMP input histogram:
destination unreachable: 6940
timeout in transit: 17
3601 ICMP messages sent
0 ICMP messages failed
ICMP output histogram:
destination unreachable: 65
time exceeded: 3536
The “destination unreachable: 6940” in the ICMP input histogram represents the statistics for receiving ICMP type 3 (ICMP_DEST_UNREACH) and code 4 (ICMP_FRAG_NEEDED), typically for cases like request A. The “destination unreachable: 65” in the ICMP output histogram represents the statistics for sending ICMP type 3 (ICMP_DEST_UNREACH) and code 4 (ICMP_FRAG_NEEDED), also typically for cases like request B.
Question 3: Why does the ICMP packet not trigger the tcp retransmission?
In Question 1, we have the details for how the Linux kernel handles the ICMP packet with type: 3 (ICMP_DEST_UNREACH) and code: 4 (ICMP_FRAG_NEEDED). It can be handled in tcp_v4_mtu_reduced(struct sock *sk)
OR
This is based on the held status of the socket tcp_ipv4.c
From the tcpdump, request A triggers TCP retransmission, which helps reduce delay duration. However, request B does not trigger TCP retransmission, resulting in a delay of more than 200ms.
To understand how the ICMP packet triggered by request B is handled and why it experiences a delay of over 200ms, we need to examine how this ICMP packet is processed in the Linux kernel:
b'tcp_v4_err+0x1'
b'icmp_unreach+0x91'
b'icmp_rcv+0x19f'
b'ip_protocol_deliver_rcu+0x1da'
b'ip_local_deliver_finish+0x48'
b'ip_local_deliver+0xf3'
b'ip_rcv+0x16b'
b'__netif_receive_skb_one_core+0x86'
b'__netif_receive_skb+0x15'
b'process_backlog+0x9e'
b'__napi_poll+0x33'
b'net_rx_action+0x126'
b'__do_softirq+0xd9'
b'do_softirq+0x75'
b'__local_bh_enable_ip+0x50'
b'__icmp_send+0x55a'
b'ip_fragment.constprop.0+0x7a'
b'__ip_finish_output+0x13d'
b'ip_finish_output+0x2e'
b'ip_output+0x78'
b'ip_local_out+0x5a'
b'__ip_queue_xmit+0x180'
b'ip_queue_xmit+0x15'
b'__tcp_transmit_skb+0x8d9'
b'tcp_write_xmit+0x3a7'
b'__tcp_push_pending_frames+0x37'
b'tcp_push+0xd2'
b'tcp_sendmsg_locked+0x87f'
b'tcp_sendmsg+0x2d'
b'inet_sendmsg+0x43'
b'sock_sendmsg+0x5e'
b'sock_write_iter+0x93'
b'do_iter_readv_writev+0x14d'
b'do_iter_write+0x88'
b'vfs_writev+0xaa'
b'do_writev+0xe5'
b'__x64_sys_writev+0x1c'
b'do_syscall_64+0x5c'
b'entry_SYSCALL_64_after_hwframe+0x44'
Upon further tracing, in the function tcp_v4_err(), the packet is handled by tcp_v4_mtu_reduced(). This occurs while the packet is still in the send context, meaning the socket is still held by the userspace, so tcp_v4_mtu_reduced() is not called directly.
tcp_v4_mtu_reduced() is invoked when the socket is released by release_sock(). In tcp_v4_mtu_reduced(), tcp_simple_retransmit() is called tcp_simple_retransmit(), but the packet is not sent out, so TCP retransmission is not triggered in this scenario, unlike request A tcp_input.c.
Upon further tracing, in this condition, the packet is sent again during the handling of the TCP probe timer, resulting in a delay of more than 200ms.
b'tcp_v4_send_check+0x1'
b'tcp_write_wakeup+0x120'
b'tcp_send_probe0+0x1d'
b'tcp_probe_timer.constprop.0+0x17e'
b'tcp_write_timer_handler+0x79'
b'tcp_write_timer+0x9e'
b'call_timer_fn+0x2b'
b'__run_timers.part.0+0x1dd'
b'run_timer_softirq+0x2a'
b'__do_softirq+0xd9'
b'irq_exit_rcu+0x8c'
b'sysvec_apic_timer_interrupt+0x7c'
b'asm_sysvec_apic_timer_interrupt+0x12'
b'cpuidle_enter_state+0xd9'
b'cpuidle_enter+0x2e'
b'cpuidle_idle_call+0x13e'
b'do_idle+0x83'
b'cpu_startup_entry+0x20'
b'start_secondary+0x12a'
B'secondary_startup_64_no_verify+0xc2'
Question 4: If the route MTU cache changes on the fly, does it impact connections that are already established?
From the tcpdump files for request A and request B, we can observe that this impacts new connections. But does it affect connections that are already established with MSS negotiated with an MTU of 1480?
Unfortunately, existing traffic will be impacted even if the MSS is negotiated with an MTU of 1480.
The MSS is periodically checked during message sending in the TCP stack: tcp_output.c
If the route MTU expires (the route MTU is cached for 600 seconds by default), the MSS will change back from 1440 (MTU 1480) to 1460 (MTU 1500). Consequently, subsequent requests may also experience the 200ms delay issue.